Research on 3D modeling of the human body
Technology and methodology for modeling the human body in 3D.
Aug, 2006
The objective of this research is to generate information about the technologies and methodologies for modeling the human body in three dimensions.
A secondary objective is to seek information about the possibility to achieve a 3D model using the least possible number of cameras.
We will try to reach a conclusion that allows the team to plan activities related to product design in a way that allows to implement 3D modeling of the golf swing in the future.
Criterion function
The reconstruction of the human body based on videos may be used in various fields such as virtual reality, recognition of gestures, choreography, rehabilitation, communication, production of movies, games and more.
On this subject, Jianhui Zhao and Ling Li, from the Computer Engineering School of the Nanyang Technological University in Singapore, made a deeper thesis on the subject.
They based their research on previous ones so that their work is a refinement of those discussed below.
Valentina Filova [1] presented an approach to generate a model based on video footage taken from an orthogonal perspective.
Chen and Lee [2] presented a method for determining the 3D location of the joints of the human body based on videos of people walking. The physiological variable were taken to determine the movement restrictions. Then use graph theory to determine a single interpretation of the data.
Robert Holt [3] adopted the technique of Divide & Conquer to decompose each articulated object into primitive (rigid or articulated), estimating the motion of these simple parts. Decompositions and estimates then spread to the body recursively. This solution does not exploits the fact that parts belong to the same individual and are interrelated.
Xiaoming Liu [4] used the correspondence between the 3D model and 2D image to calibrate the camera and to construct a sequence of movements in 3D perspective. The effectiveness of the model has yet to be tested in random positions of the body, especially those in which the triangle formed by the shoulders and chest are melted.
Camillo J. Taylor [5] does not assume that the images are taken with a calibrated camera which means that the system can be used in photos obtained from the web or scanned. The method assumes that the relationship between points of the scene and its corresponding image can be modeled as a scale orthographic projection. Not suitable for use in situations where there are significant perspective effects. It also requires the user to specify which segment is the closest to the camera.
The novelty of the approach proposed by Zhao and Li is based on a hierarchical model for the reconstruction of human body posture based on images captured using a single camera. Was decided to explore this last solution because of the various problems presented earlier. We also managed to contact the project leaders who provided additional information to that found on the web.
This model uses a human skeleton with encoded biomechanical constraints on the various joints.
The angular change of the joints in the same coordinate system is obtained between consecutive segments in a hierarchical manner through matrix transformations.
The skeleton used contains 17 joints and 16 segments. It is assumed that we have geometric information of the individual (eg. length of each body segment).
The body can be represented as a tree of rigid parts connected by specific joints. Each rigid part is allowed to move freely in their own domain on its immediate ancestor.
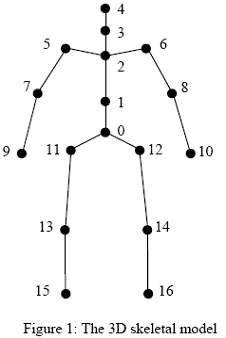 |
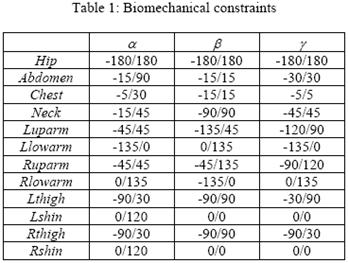 |
Each joint has three biomechanical constraints representing the angles of rotation about the axes X, Y, Z in its local coordinate system (a,b,g).
Biomechanical constraints are important to construct the model since it decreases the solution space, but is not sufficient to determine the exact position of the body. For these reason we will user the concept of "Criterion function".
To define this concept will use the following notation:
- segment_imgi is the vector representing the body segment i in the 2D image.
- segment_proji is the vector representing the projection of segment i in the 3D model.
- position_imgi is joint position i in the 2D image.
- position_proji is joint position i in the 3D model.
- Delta_scale is an array of weight parameters.
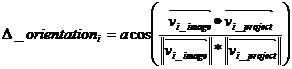
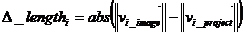
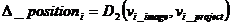
This set of definitions lead to the "Criterion function":
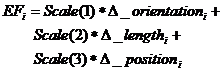
where scale (n) are weight parameters that alter the result by segment and the joint on which you are working. Sometimes the movement of a segment or other affected joint so that the formula should be applied to the entire branch of the tree that is affected (may even come to affect the whole tree).
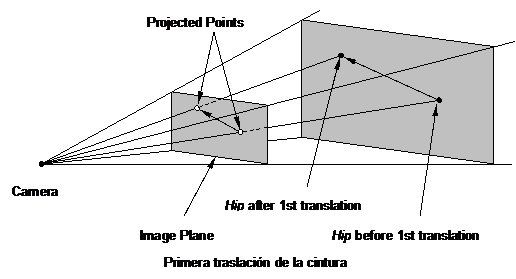
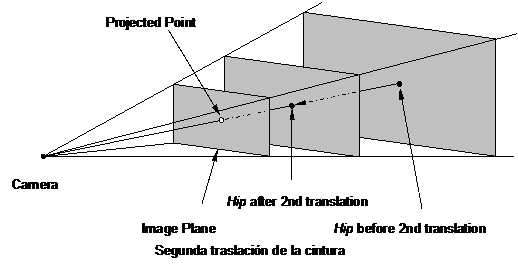
Standard ISO/IEC FCD 19774:200X (H-ANIM)
This standard comes from the need to represent humans in virtual environments via the web. This standard specifies the way of representing humanoids using VRML97.
The document layout is based on three basic principles are: compatibility, flexibility and simplicity.
The human body is defined by segments which are connected by hinges. Encourage these humanoid pair simply necessary joints access and alter the angle between the two connecting segments.
A humanoid is composed of the following objects:
Humanoid is the root of the body and provides support to other body parts. Joint: is related to the root of the body and joints with other objects through objects Segments. Segment: Specifies the physical attributes of the connections between the joints. Site: Allows you represent items such as clothing, cameras and jewelry on the body. Displeasure: this object contains information about the range of motion allowed for the object within which it is located.
Basically, the standard defines a tree of segments connected by joints that define the set of transformations which move from the root to each of the humanoid body appendages.
There are different levels of articulation (LOA: Level of Articulation). For example we can define a humanoid with 14 joints (low joint) to a humanoid with 72 joints (high level of articulation).
Conclusion
Because the 3D modeling of the swing was established as an additional project scope, the result of research carried out allow to generate the knowledge needed to begin work on the 2D model.
As a result of knowledge gained from the analysis of Criterion Function and the h-anim standard we have reached to the following conclusions.
Generating the 2D model and the various metrics related to the golf swing will strengthen the concepts learned about the structure of the human body and the relationship between its parts. We will also generate a number of general classes and tools to facilitate the work of building the 3D model.
The 3D model will be generated as an independent module that will communicate in the future with the 2D model via an interface. The idea is generate the 2D model so the resulting information from both, the model and the different metrics, will be stored before being consumed by the 3D model.
We will try to stay within the standard h-anim as much as possible, especially in the representation of the various parts of the body and the relationship between these.
[1] Valentina Filova, France Solina, Jadran Lenarcic, Automatic reconstruction of 3D human arm motion from a monocular image sequence, Machine Vision and Applications (1998) 10, 1998, 223-231.
[2] Zen Chen and His-Jian Lee, Knowledge_Guided Visual Perception of 3-D Human Gait from a Single Image Sequence, Systems, Man, and Cybernetics, IEEE Transactions, Vol. 22, No. 2, March/April 1992, 336-342.
[3] Robert J.Holt, Arun N.Netravali, Thomas S.Huang, Richard J.Qian, Determining Articulated Motion from Perspective Views: A Decomposition Approach, IEEE Workshop on Motion of Non-Rigid and Articulated Objects, 1994, 126-137.
[4] Xiaoming Liu, Yueting Zhuang, and Yunhe Pan, Video Based Human Animation Technique, Proc. of the 7th ACM International Multimedia Conference, Orlando, Florida, USA, October 30-November 5, 1999.
[5] Camillo J. Taylor, Reconstruction of Articulated Objects from Point Correspondences in a Single Uncalibrated Image, Computer Vision and Image Understanding 80, 2000, 349-363.
